Subtotal 0 рсд

U svetu veštačke inteligencije, postignuća koja su se dogodila u poslednjih nekoliko godina, pogotovo od 2022. donela su revolucionarne promene u načinu na koji AI razume i rešava probleme. U ovom tekstu istražujemo kako je spoj igranja igara i razumevanja jezika doveo do ključnih proboja u razvoju AI, posebno fokusirajući se na model-based učenje, Monte Carlo Tree Search (MCTS) i kako su ovi koncepti oblikovali moderne LLM.
Definicija rezonovanja (zaključivanja) Reasoning
- Rezonovanje se može definisati kao proces povezivanja misli jedna na drugu, koje vode do tačnog zaključaka. Dobrim rezonovanjem nazivamo niz koji možete podeliti (sekvence) i da neko drugi može da prati te sekvence i dođe do istog zaključka samostalno.
Kada sam se prvi put igrao sa AI modelima poput ChatGPT, primetio sam da je imao problema sa jednostavnim testovima rezonovanja. Na primer, kad sam ga zamolio da igra X-Oks i pokuša da izgubi, nije mogao da se izvuče iz svojih čvrsto naučenih obrazaca, kao što je igranje da bi pobedio.
Ova situacija je otkrila jedan od ključnih nedostataka prvih AI modela: njihova nesposobnost da razmišljaju fleksibilno. Na sličan način, mnogi su primetili da su prvi LLM-ovi često propadali na jednostavnim problemima, kao što su problemi sa “blokovima”, koji zahtevaju planiranje više koraka unapred. Kada se suoče s problemima koji zahtevaju više od osam koraka za rešenje, AI često proizvodi “razumljivu” glupost, što je znak slabog rezonovanja.
Model sveta i algoritam
- Model sveta možete zamisliti kao simulator – predviđa kako će okruženje reagovati (promeniti se) kao odgovor na akcije.
- Algoritam je proces donošenja odluka koristeći takav model sveta.
Uzmimo računarski šah kao primer. Model sveta je jednostavan – definisan je pravilima šaha plus opisom table. Možete mu dati položaj svih figura i sledeći predloženi potez, a on daje novo stanje table i eventualne bodove koje je svaki igrač dobio ili izgubio. Algoritam vam govori kako da pravite poteze.
Jednostavan šahovski algoritam bi gledao unapred svaki mogući sledeći potez koristeći model sveta, proveravao vrednost rezultirajuće table, a zatim pravio potez sa najboljom vrednošću – poznat kao “pohlepni” pristup.
Monte Carlo Tree Search (MCTS)
1987. godine, Brus Abramson u njegovom PhD je predložio radikalnu ideju: šta ako samo isprobate neke nasumične igre da vidite šta se dešava?
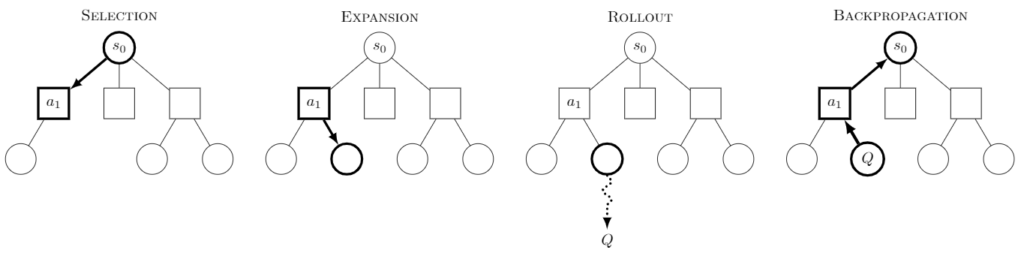
Na primer, u šahu, ako razmišljate o pomeranju konja, odigrali biste stotine nasumičnih igara nakon tog poteza da vidite koliko često pobedite. Isto biste učinili za svaki mogući sledeći potez, a zatim jednostavno izabrali potez koji je doveo do najviše pobeda.
Ovo je bilo malo manje precizno nego pretraživanje celog stabla (što je bilo nemoguće), ali je zahtevalo samo delić posla. Ovi nasumični prolazi, poznati kao “rollouts”, nudili su način da se proceni snaga poteza bez analiziranja svake moguće budućnosti.
AlphaGo
Međutim, proboj bi došao kombinovanjem Monte Carlo pretrage stabla sa neuronskim mrežama koje smo ranije videli, koristeći intuiciju i za poziciju i za poteze da usmeravaju rollouts ka najperspektivnijim pravcima.
Ovo je dovelo do ključnog eksperimenta u istoriji igara i veštačke inteligencije – AlphaGo. Premisa je bila jednostavna: koristite veće neuronske mreže da naučite i intuiciju za poteze, zatim ih koristite za efikasno vođenje Monte Carlo pretrage stabla. Kao rezultat, sistem je mogao brzo donositi odluke u jasnim situacijama, dok je više vremena za razmišljanje ili simulaciju posvećivao složenim pozicijama gde bi dodatna analiza donela više informacija – baš kao što bi to učinio ljudski igrač.
Ovo je rezultiralo računarskim programom koji je imao i velemajstorsku intuiciju za igru sa nadljudskom sposobnošću pretrage. Ne samo da je pobedio najbolje ljude, već je doveo do nekoliko izuzetnih poteza, najpoznatiji je potez 37 u drugoj igri protiv Li Sedola. Ovaj potez je bio toliko neobičan i kreativan da je zapanjio stručne igrače.
Alpha Zero
Alpha Zero je sledeći korak u razvoju AI od novembra 2019., koji je mogao da uči bilo koju igru bez prethodnog znanja o pravilima. Ova sposobnost je omogućila Alpha Zero da razvije model sveta zasnovan na sopstvenim iskustvima, što je dovelo do generalizacije učenja preko različitih igara.
Jedna od ključnih inovacija u AI je sposobnost da se razvije “model sveta”. Ovaj model kao što smo naveli, predviđa kako će se okruženje promeniti kao odgovor na akcije. U tom smislu, svet može delovati kao simulator, omogućavajući AI da testira različite scenarije pre nego što donese odluku.
Ključna ideja bila je ne samo naučiti model sveta da ubrza početni trening, već ga koristiti i tokom igre za simulaciju mogućih poteza, kao što su to radili od AlphaGo. Da bi pokazali opštost, isprobali su ga ne samo na klasičnim igrama na tabli kao što su šah, go i šogi, već i na 57 Atari igara, sve koristeći istu neuronsku mrežu.

Ovo je omogućilo AlphaZero-u da “predviđa” kroz grane bilo koje igre koristeći model koji je sam otkrio iz iskustva. Dok je ovo bila moćna i uzbudljiva metoda, i dalje je postojao ključni problem: nije bilo prenosivog učenja, što znači da poboljšanje u jednoj igri nije pomagalo da se bolje igra druga igra. Alpha Zero je morao da trenira iz početka za svaku novu igru koju je učio, stvarajući izolovane silose veština. To je bilo zato što je model sveta koji je naučio bio nefleksibilan.
ChatGPT i opšti model sveta
Ono što je još uvek bilo potrebno bio je veoma opšti model sveta, sličan ljudskom umu, što nas vraća na ChatGPT – sistem koji je treniran da predviđa podatke koje generišu ljudi širom weba, opštiji od bilo čega pre toga.
Eksperimenti sa LLM otkrili su nešto iznenađujuće: ovi sistemi mogu efikasno simulirati bilo koji model sveta koji bismo mogli trebati, sa obzirom na bilo koji kontekst. Ne samo to, već su mogli da procenjuju situacije i predlažu razumne akcije koje treba preduzeti u bilo kojoj situaciji.
Chain-of-Thought rezonovanje
“Razmišljanje” korak po korak na kraj upita.
Ovo je prisililo model da razbije probleme na niz jednostavnijih misli. Dok je ovaj osnovni “lanac misli” poboljšao performanse na zadacima rezonovanja, i dalje je postojalo brzo intuitivno razmišljanje, koje je često vodilo do pogrešnog zaključka – kao što smo videli u igri iks-oks.
Tree-of-Thought
Ovo je dovelo do eksperimenata koji su primorali LLM da radi neku vrstu razmišljanja poznatu kao “drvo misli”. Umesto da sledi samo jedan lanac “misli”, sistem je mogao da istražuje više puteva rezonovanja, a zatim koristi sam jezički model da proceni koji put izgleda najperspektivnije.
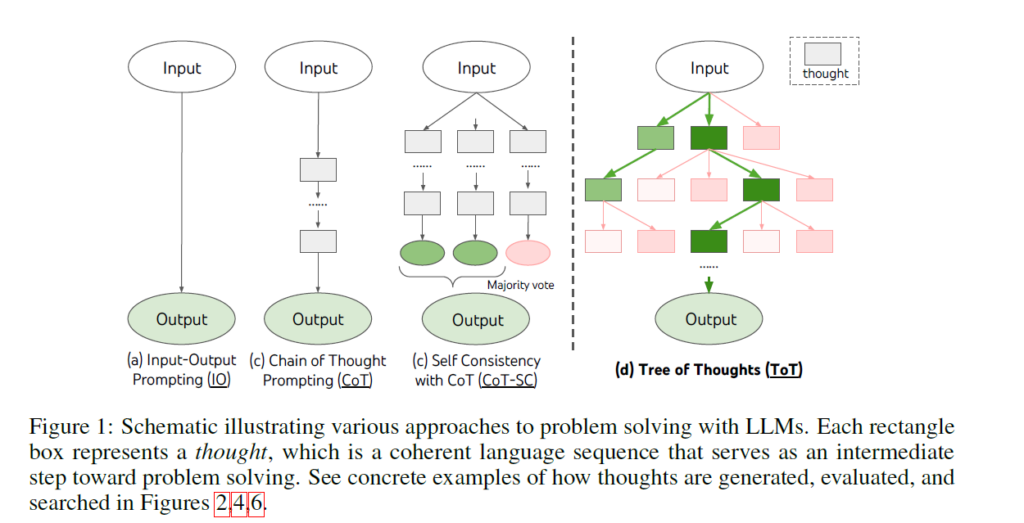
I tu su se svi delovi spojili zajedno, spajajući rezonovanje u igrama sa razumevanjem jezika. Mogli smo da prilagodimo tehnike veštačke inteligencije za igre, poput Monte Carlo pretrage stabla, za istraživanje lanaca misli, slično tome kako je AlphaGo pretraživao kroz moguće sekvence potez
- Umesto simuliranja sekvenci POTEZA, sistem je sada mogao da simulira korake REZONOVANJA, istražujući i procenjujući različite puteve logike pre nego što se odluči za najverovatniji (perspektivniji).
Uloga Reinforcement learning
Reinforcement learning igra ključnu ulogu u unapređenju strategija rezonovanja. Slično kao što ljudi uče kroz interakciju i društvene signale, AI modeli su osnaženi kroz povratne informacije o njihovim rezonovanju.

- Ključni aspekt ovog procesa je nagradni signal, koji pomaže AI da proceni svoje korake i prilagodi strategije na osnovu uspeha ili neuspeha.
Revolucionarni rad OpenAI-ja pod nazivom “Let’s Verify Step by Step” iz maja 2023. ukazao je na uzbudljiv sledeći korak: modeli su se bavili problemima rezonovanja generišući lanac misli i dobijali povratne informacije za svaki korak u svom procesu rezonovanja, postepeno otkrivajući bolje strategije razmišljanja.
Ovo je dovelo je do dramatičnih poboljšanja sposobnosti rezonovanja. Današnji modeli mogu da se nose sa zadacima koji su pre samo nekoliko godina izgledali nemoguće, a ovo je potvrdilo neke pretpostavke da duže razmišljanje poboljšava performanse.
Pomeranje granica
Svaki napredak u sposobnosti rezonovanja primorava nas da tražimo nove izazove koji pomeraju granicu dalje. Ovo je podstaklo istraživače da razviju nove izazove, poput ARK testa, gde sistemi moraju da otkriju obrasce koje nikada ranije nisu videli, primoravajući ih da rezonuju iz početka, umesto da se oslanjaju na zapamćena rešenja. Napredak u rešavanju ovih problema se postojano poboljšava.
Razvoj veštačke inteligencije kroz učenje o modelima sveta, MCTS i uvođenje novih pristupa rezonovanju kao što su “Chain-of-Thought” i “Tree-of-Thought” predstavlja značajan napredak u razumevanju kako AI uči i razmišlja. Kako se istraživači i dalje suočavaju sa novim izazovima, možemo očekivati da će AI postati sve sposobniji u rešavanju kompleksnih problema, otvarajući nove horizonte za primenu u različitim oblastima.
Ovaj napredak takođe postavlja važna pitanja o prirodi inteligencije i razumevanja. Da li je važno kako AI dolazi do rešenja, ili je samo output (rezultat) ono što se računa? Ova debata će sigurno oblikovati budućnost razvoja veštačke inteligencije.
Blog post je inspirisan ovim video koji je sniman u Novembru 2024, pre 01 i 03 Reasoning modela kao i Deep Search, Sonnet 3,7 etc.